아는 게 많은 ChatGPT, 정작 우리 회사 일은 모른다
생성형 AI를 업무에 활용해 본 적이 있다면, 한 번쯤 이런 경험을 해보셨을 겁니다. 분명 똑똑하게 답을 잘하는데, 정작 ‘우리 회사 작년 매출 보고서 요약해줘’ 같은 질문 앞에서는 무력해지죠. ChatGPT, Gemini, Claude 같은 Public AI는 인터넷에 공개된 지식을 학습하므로, 우리 조직 내부에만 존재하는 기밀 데이터나 고유 자료를 알지 못하기 때문입니다.
결국 AI를 제대로 활용하려면, 우리 조직의 데이터를 AI에 안전하게 학습시킬 수 있어야 합니다. 그런데 흩어진 데이터를 어떻게 모을지, 권한 없는 사람에게 정보가 새지 않게 하려면 어떻게 할지, 신뢰할 수 있는 결과를 얻으려면 무엇을 신경 써야 할지까지, 막상 들여다보면 넘어야 할 과제가 적지 않습니다. 그래서 오늘은 파수 AI 김용길 본부장이 제시하는 AI 도입의 현실적인 과제와 그 해법인 ‘AI 데이터 인프라’ 개념을 다뤄보겠습니다.


모델보다 데이터, 그리고 ‘따로 또 따로’의 함정
가장 먼저 알아야 할 점은 AI 활용의 성패가 어떤 데이터를 주는지, 즉 ‘데이터 피딩 (Data Feeding)’에 달려 있다는 사실입니다. 아무리 뛰어난 모델이라도 공급되는 데이터의 품질이 낮으면 쓸 만한 결과물을 얻을 수 없습니다.
문제는 데이터를 학습시키는 방식입니다. 많은 조직이 인사, 재무, 영업, 품질 등 부서별로 AI 에이전트를 도입하고 있는데요. 이렇게 되면 에이전트마다 데이터셋을 별도로 구축해야 하고, 에이전트 수가 늘어날수록 데이터 가공과 투입에 공수가 배로 듭니다. 비효율이 눈덩이처럼 불어나는 구조인 셈이죠.
그래서 통합된 ‘AI 데이터 인프라’가 필요합니다. 부서마다 데이터를 따로 쌓는 대신, 한 번 잘 구축한 전사 데이터 인프라 위에 어떤 AI 에이전트든 즉시 연결하는 방식인데요. 새 에이전트가 필요하면 API 연계만으로 바로 도입할 수 있고, 중복 데이터셋을 만들 필요가 없으며, 신규 에이전트를 무제한으로 확장할 수 있습니다. 개별 도입 방식에 비해 한층 효율적인 구조입니다.
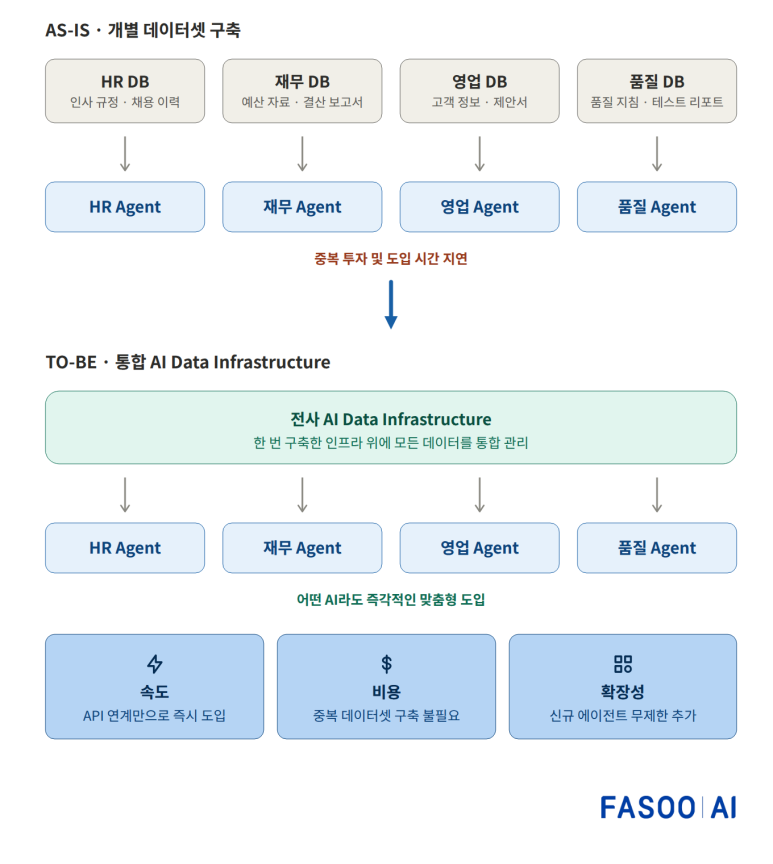
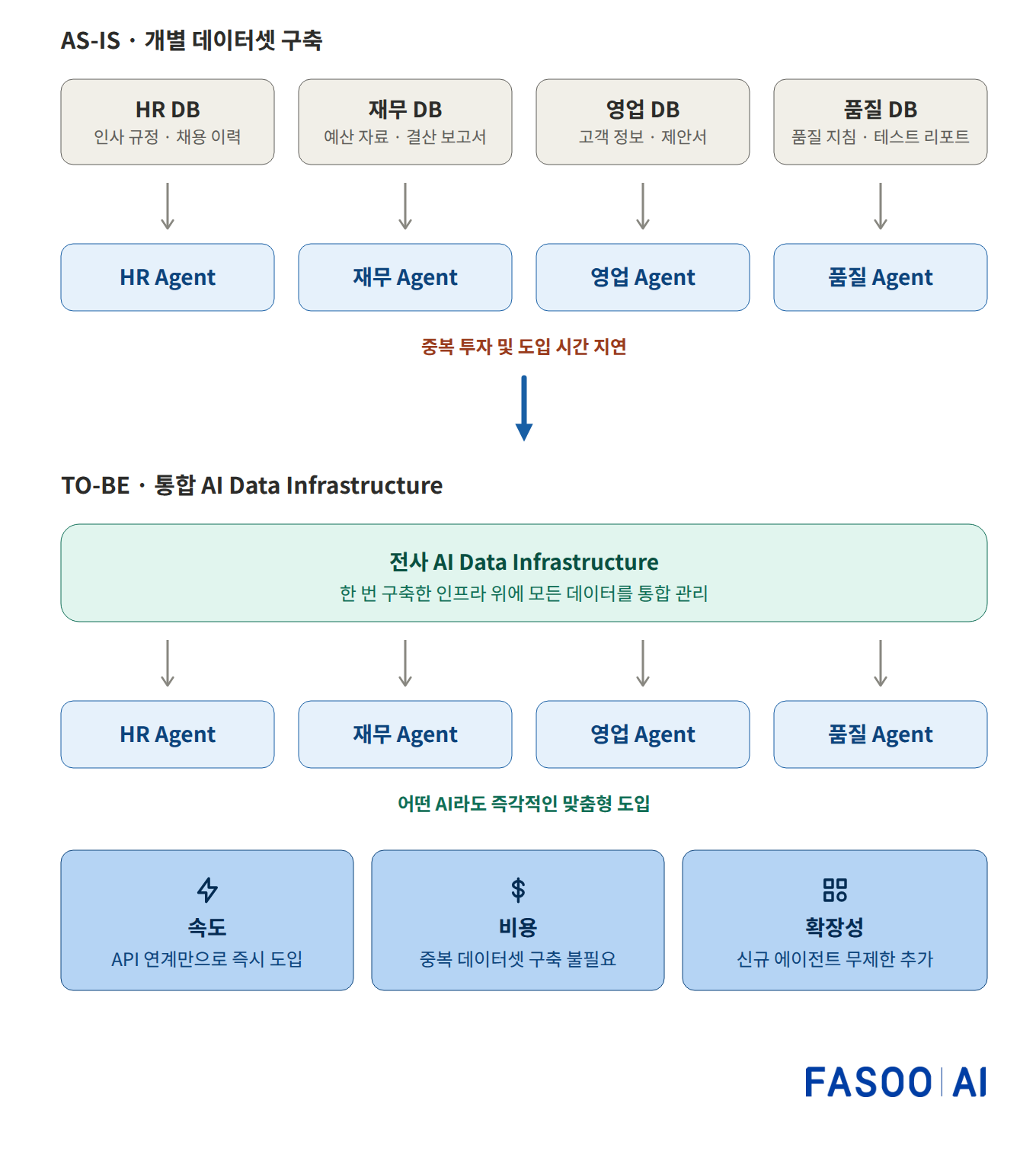
통합 AI 데이터 인프라의 구조
AI 데이터 인프라가 갖춰야 할 3가지 요건
그렇다면 좋은 AI 데이터 인프라는 무엇을 갖춰야 할까요? 김용길 본부장은 3가지 요건을 짚었습니다.
첫째, 데이터 취합 (Quantity)입니다. 기업 데이터는 정형 데이터 (DB)와 비정형 데이터 (문서)로 나뉘는데, 특히 문서 같은 비정형 데이터를 AI가 잘 활용하려면 내용 기반의 분류와 태깅이 필요합니다. 또 한 가지 중요한 건 ‘실시간 최신화’입니다. 매일 새 문서가 만들어지고 기존 문서는 수정되는데, 이걸 부서별로 수동 업데이트하면 유지보수 비용이 상승하기 때문입니다. 물론, 더 이상 유효하지 않은 폐기 데이터가 AI 답변에 섞여 들어가는 일도 막아야 하죠. 그렇다면 어떻게 모든 문서를 수동 작업 없이 항상 최신 상태로 유지할 수 있을까요?
둘째, 접근 권한 (Security)입니다. 전사 데이터를 통합하려면, 부서와 직급에 따라 접근 권한을 반드시 통제해야 하는데요. 권한 체계가 없으면 모든 직원이 AI를 통해 모든 문서를 열람할 수 있기 때문입니다. 예를 들어 연봉 정보가 담긴 자료를, 권한 없는 타 부서 직원이 AI의 요약ㆍ답변 형태로 확인하게 되는 상황도 발생할 수 있습니다. 게다가 Word, PPT, PDF 같은 일반 문서는 파일 자체에 정교한 권한 체계를 갖추기 어려워, AI가 질의 시점마다 사용자 권한을 검증할 수단도 마땅치 않습니다. 그렇다면 권한 없는 사용자가 AI를 경유해 기밀에 접근하는 것을 어떻게 막을 수 있을까요?
셋째, 결과 품질 (Quality)입니다. 단순히 데이터가 많다고 좋은 게 아닙니다. AI가 불필요하거나 중복된 데이터, 특히 구버전과 최신본이 뒤섞인 데이터를 참고하면 거짓 정보를 만들어내는 환각 (Hallucination) 현상이 발생합니다.
그래서 중요한 것이 메타데이터입니다. 문서의 생성자ㆍ시점ㆍ부서 같은 메타데이터를 활용하면, 질의에 가장 적합한 최신 데이터만 골라 AI에 전달할 수 있습니다. 메타데이터가 어떤 데이터를 AI에 넘길지 판단하는 기준이 되는 겁니다. 다만 방대한 메타데이터를 사람이 일일이 부여하는 일은 현실적으로 지속하기 어렵습니다. 그렇다면 어떻게 사람의 수작업 없이, 적합한 데이터만 골라 AI에 전달할 수 있을까요?
결국 이 3가지 (QuantityㆍQualityㆍSecurity)는 따로 떨어진 과제가 아니라, 하나의 시스템에서 동시에 만족돼야 하는 요건입니다. 통합된 데이터를 안전하게, 고품질 상태로 제공하고 통제할 수 있어야 합니다.
기존 방식으로는 왜 부족할까
시중에는 이미 데이터를 모으는 여러 방식이 있습니다. 모든 파일을 단일 저장소로 강제 이관해놓고 AI에 학습시키는 ‘문서 중앙화’ 방식, 그리고 모든 형태의 데이터를 원시 상태로 모아두고 활용하는 ‘데이터 레이크’ 방식이 대표적이죠.
하지만 두 방식 모두 데이터 취합과 최신화에 집중할 뿐, 그 다음 단계는 해결하지 못합니다. 신규 데이터를 실시간으로 반영하는 체계, 권한 기반 필터링, 메타데이터 자동 분류ㆍ태그 체계도 없을뿐더러, 통합 운영에 드는 공수도 과도합니다. 앞서 짚은 3가지 과제를 근본적으로 해결하지 못하는 방식입니다.


Wrapsody, 세 가지 요건을 하나의 솔루션에서
파수 AI의 Wrapsody는 바로 이 지점에서 출발합니다. 데이터 최신화, 접근 통제, 품질 관리를 인프라 차원에서 자동으로 해결하는 AI 데이터 인프라 솔루션이죠.
• 데이터 최신화
: 고유 ID 기반의 버전 관리로, 문서가 생성ㆍ수정되는 즉시 백그라운드에서 동기화돼 항상 검증된 최신 문서만 AI에 전달
• 접근 통제
: 자동 ACL 생성으로 권한 없는 사용자의 우회 접근을 차단하며, AI 질의 시점마다 사용자의 현재 권한을 실시간 검증해 인가된 데이터만 AI에 전달
• 품질 향상
: 메타데이터 및 태그 자동 생성으로 AI 검색 정확도를 극대화. 딥러닝 기반으로 핵심 문맥과 키워드를 추출하고, 문서의 생애주기를 추적해 구형 데이터의 오남용 방지
Business-Ready AI Agents
물론 Wrapsody라는 인프라 위에 다양한 AI 에이전트를 올릴 수도 있습니다. 전사 지식에 실시간으로 접근해 업무를 보조하는 Wrapsody K-Assistant, 흩어진 사내 문서를 주제별로 체계화하고 의도에 맞게 찾아주는 지능형 문서 사서 Wrapsody Librarian, 그리고 특정 도메인에 정통한 전문가 봇을 직접 생성할 수 있는 Domain Knowledge Master까지. 실제로 파수 AI는 사내에서 영업 마스터, 제품 가이드 마스터 등 44개의 에이전트를 운영하고 있습니다.
여기에 더해 Fireside는 Wrapsody의 모든 기능을 메신저 인터페이스로 옮긴 솔루션입니다. 비즈니스 메신저인 동시에 AI 메시징 허브로, 사무실 밖에서도 스마트폰으로 동일한 AI 경험을 누릴 수 있습니다. Wrapsody의 데이터 최신화ㆍ접근 통제ㆍ품질 향상 기술을 그대로 품은 채, 언제 어디서나 질의할 수 있는 창구가 되는 것이죠.
결국 기업이 AI를 제대로 활용하려면, 가장 먼저 ‘데이터’를 준비해야 합니다. 그리고 그 데이터를 흩어짐 없이 통합하고, 권한에 맞게 통제하며, 신뢰할 수 있는 품질로 전달하는 체계가 바로 ‘AI 데이터 인프라’입니다. AI가 우리 회사의 일을 제대로 돕기 시작하는 것은, 이 인프라가 갖춰진 다음부터입니다.
파수 AI는 기업이 안전하고 탄탄한 AI 데이터 인프라를 갖출 수 있도록 함께합니다. AI를 제대로 활용하는 첫걸음, 파수 AI와 함께 시작해 보세요.

